
Introduction
I recently had the privilege of being interviewed by Linda Rosencrance from MSDynamicsWorld.com about how my employer has adopted Dynamics NAV and my experiences with customization and development. The topic of source control came up, which I thought would make an interesting two-part series for my blog. My coworker has already started a great series on our custom source control solution, so rather than rehash his excellent overview, I want to focus specifically on one of the challenges we faced: parsing and sorting nav object dependencies. This series will cover the following:
- Part 1 – Parsing NAV object dependencies (this post)
- Part 2 – Sorting NAV object dependencies
Background
When our team first began working with NAV a few years ago (NAV 2009 R2), our first reaction was “What do you mean it has no source control?” (well ok, that was probably the second reaction, behind the occasional bouts of profanity due to the lack of undo functionality in the code editor…). We were very surprised to hear that most developers worked in a shared database and the closest thing to source control was using a locking mechanism, which prevented anyone else from working on the given object while one person had write access. There are times when this can be advantageous (for example, locking binary objects that cannot be merged), but being forced to use this model exclusively does not work well in practice for a system under constant change (at least in my experience). When you factor in that more than a couple of developers on our team are actively working on the system, this just makes a locking approach even less practical. Still, we gave it a shot for a while, but ultimately, this was a no-go for us.

We quickly realized that our workflow often required many developers to be working on the same objects simultaneously, which meant each developer needed to work in an isolated database. Working locally with an isolated database means you need to address merging changes from other developers. It needs to relatively quick and easy. This lead us to create a custom tool to act as a bridge between the Dynamics NAV database housing the objects and our distributed version control system (Kiln, a tool built on top of Mercurial), which works well with text files. While it is true that NAV 2015 is offering a way to create Deltas using PowerShell and some handy cmdlets, this was not an option for us a few years ago (and we are still using NAV 2013 R2 at the moment). Also, with our current custom solution, we get the added benefit that the changesets (Mercurial’s equivalent to Deltas) are fully integrated with Mercurial, giving us a full history of all changes (with commit messages), branching abilities, relatively easy merging and hooks into our bug tracking software, FogBugz.
Parsing NAV Object Dependencies
The main focus of this post is to talk about a challenge we faced, which was the need to parse NAV objects for dependencies. I would like to cover why we need to do this and how we did it.
Why Do We Need to Parse Object Dependencies?
The first question is “Why do we need to parse NAV object dependencies?”. To answer this question, we need a little background information on how our source control tool actually works. Lets use a hypothetical example:
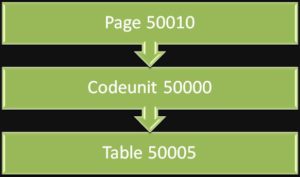
Suppose a programmer, we’ll call him Skip List, makes a change to codeunit 50000, table 50005 and page 50010. We’ll also say that page 50010 references codeunit 50000, which in turn references table 50005. When Skip exports his changes, he doesn’t want to export each object individually, but rather wants to export all three functionally related objects at once (our tool exports each object as individual text files, but does it in a single export command). When Skip commits his change to the repository, it groups all three files, their Deltas, the commit message and some other metadata into a single changeset. Skip then pushes his changes to the remote repository for the other developers to pull down his changes whenever they are ready.
Meanwhile, Beatrice Tree (her colleagues call her B-Tree) has arrived for work a little later in the day (she had a dentist appointment and then got caught in a crazy traffic jam that involved a fight between a squirrel and a goat… long story). The first thing she does before beginning her work is to get any new changes from the remote repository to her local repository and import them into her database. She issues a pull command to mercurial, gets the changes Skip had pushed earlier, updates her local repository with his changes (merging if required) and then does an import into her local NAV database. Most of this is handled directly from our custom tool. Now since the three objects will be imported and compiled as individual files, it is important that they are handled in the proper order. If page 50010 is compiled before codeunit 50000 or codeunit 50000 is compiled before table 50005, we’ll get a compile error (depending on the nature of the changes of course).
To ensure that the objects are compiled in the proper order, the first step is to figure out which objects in the list of text files being imported depend on each other. This is why we need to parse the files and figure out the dependencies. You can imagine this gets much more complicated when you start pulling in multiple changesets at once with more than one developer changing the same object.
How Do We Parse Object Dependencies?
In my previous post, I talked about finite state machines and how my preferred implementation was the State Pattern when working with Object Oriented languages. Since we wrote our tool using C#, this allowed me to do just that.
There is quite a bit of code behind the entire parsing strategy and how it ties into our tool, so I’m going to attempt to do a shallow overview to give an idea of how everything works at a basic level. Hopefully this is enough to get you started if you are interested in doing something similar.
Parser Strategy Overview
First it makes sense to show the processes surrounding the parsing:
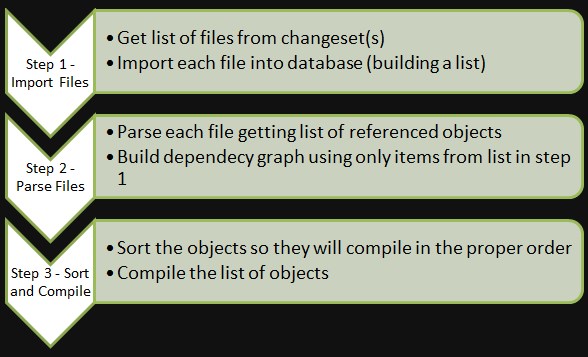
Before parsing, we have finished step 1, which gives us a list of all files (and by extension, all objects) that have been imported into the database. It should be noted that the same objects may have been imported multiple times if they appeared in multiple changesets (either multiple commits by the same author and/or changes done by another developer). Step 3 will be the topic of my next post. For this post we are concerned with step 2.
The parser we built doesn’t go to the extreme level of building abstract syntax trees or interpreting and transforming the code etc. It is very basic in that it only attempts to pull out references to other objects and builds a dependency graph. As it is building the graph, it is only interested in objects that are part of the current list of objects that were imported into the database, which will need to be compiled.
Unfortunately, we were not able to find a formal grammar definition of the C/AL language, so we used a little trial and error in order to come up with a fairly generic (for all object types), but reliable structure for the text file layout for NAV objects. We broke the objects down into the following sections:

These sections each represent a state in our state machine. Each of these states will perform some similar functionality. The state machine follows this general flow:
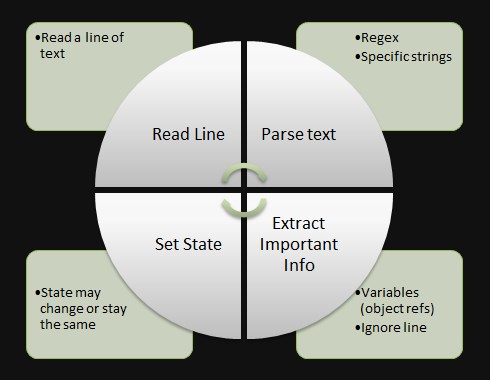
- Read a line of text
- Parse the text
- Determine if the current line has important information for the given state (e.g. find out what the current object is, locate references to other objects etc.)
- When a certain condition is met, set the state machine into another state (or you may reach the end of the file(s))
Parser State Classes
In order to create this state machine, we’ll need to create the following classes (it may be helpful to look at text file export of a NAV object to follow along):
- ParserState abstract base class
- ObjectHeaderState class
- Pulls out the current NAV object from the list of imported objects to become part of the dependency graph (we use a regex for this to grab the object type and the object id).
- Sample line: “OBJECT Codeunit 50000 My Codeunit of Wonders”
- Sets the state to ObjectPropertiesState class when the string “OBJECT-PROPERTIES” is read (case-insensitive string check).
- ObjectPropertiesState class
- Nothing notable to pull out (at least in our implementation).
- Waits for the regular properties to begin (via the string “PROPERTIES”) to set the state to PropertiesState class.
- PropertiesState class
- Looks for source table references (e.g. “TableNo=27;” or “SourceTable=Table27;”) and adds them to the dependency graph if they are included on the list of imported objects.
- Looks for the string “=VAR” to prepare for any variable declarations on the upcoming lines (inside of actions, triggers etc.).
- Parses variables, adding objects to the dependency graph if they are included on the list of imported objects.
- Looks for the string “CODE” when we are not looking for variables, to set the state to GlobalVariablesState class.
- NOTE: Just realized we are not handling “RunObject” in action definitions! The side benefit of writing a blog.
- GlobalVariablesState class
- Looks for the string “=VAR” to prepare for any variable declarations on the upcoming lines (basically all of the global variables).
- Parses variables, adding objects to the dependency graph if they are included on the list of imported objects.
- Looks for the string “PROCEDURE” to set the state to ProceduresState class (note: this is the Functions section mentioned in the NavObjectStates diagram).
- ProceduresState class
- Needs to deal with nested levels (to know when we are inside a procedure’s variable declarations, inside the procedure code or completely outside of a procedure).
- Looks for the string “VAR” to prepare for any variable declarations on the upcoming lines (inside of actions, triggers etc.).
- Parses variables, adding objects to the dependency graph if they are included on the list of imported objects.
- If we are at a nested level of 0 (outside of any procedures), and we hit the string “BEGIN”, set the state to CommentBlockState class.
- CommentBlockState class
- We’re not currently doing anything with comments, but you could potentially use it for something.
Here is a sample of the ParserState class. I have elided some of the code that isn’t relevant to get the gist of it. We aren’t focusing on implementation details, or this will turn into a huge multi-part series (maybe if there is enough interest in this, I will consider a full-fledged tutorial).
Here is a sample of the class used to parse the object header section, which is at the top of every text file. It is represented by the ObjectHeaderState class.
I will show one more state class, but then we must move on to the Parser class itself. Here is the GlobalVariablesState class.
Parser Class (Context Class)
With all of these state classes, we need to have a single driver that contains them and makes use of them (the Context class in the State Pattern). For our parsing code, this is the actual Parser class. The implementation of this class that I have chosen looks like this:
There is not really a lot going on in this class, even though it may initially appear so. It essentially does the following:

Holds a reference to each available state.
Passes itself into each state’s constructor so they can call SetState and add objects to the dependency graph (via the CurrentObject property and the ObjectDependencyManager property, which will be covered in the next blog post when we talk about sorting the dependencies).
Reads each line using the current state’s implementation of ReadLine (polymorphism, yay!). As each state reads a line, it will perform the actions we talked about earlier in the post and change the Parser’s _currentState variable automatically as we move through the file. This makes the Parser class seem like it wears many hats, but the calling class is exposed to a simple API.
That wraps up part 1. In Part 2 – Sorting NAV object dependencies, we will cover sorting and also touch on how the Parser class is created and used.